1. JPA를 이용한 리포지터리 구현
애그리거트를 어느 저장소에 저장할 지에 따라 리포지터리를 구현하는 기술은 다양하나, 도메인 모델과의 구현시 가장 선호하는 기술은 JPA라고 할 수 있다. 데이터 보관소로 RDBMS를 사용할 때 객체 기반의 도메인 모델과 관계형 데이터 모델 간의 매핑을 처리하는 기술로 ORM 만한 것이 없다.
ORM (Object Relational Mapping) 객체와 관계형 데이터베이스의 데이터를 매핑해주는 것으로, 자바 ORM 표준인 JPA가 있다.
모듈 위치
2장에서 언급한 것처럼 리포지터리의 인터페이스는 애그리거트와 같은 도메인 영역에, 실제 구현한 클래스는 인프라스트럭처 영역에 속한다.

리포지터리 기본 기능 구현
-
ID로 애그리거트 조회하기
애그리거트가 존재하면 해당 Entity를 리턴하고 존재하지 않으면 null을 리턴한다. null을 사용하고 싶지 않다면 Java 8의Optional`을 이용해서 값을 리턴해도 된다. -
애그리거트 저장하기
애그리거트를 수정한 결과를 저장소에 반영하는 메서드는 추가할 필요가 없다. JPA를 사용하면 트랜잭션 범위 안에서 변경한 데이터를 자동으로 DB에 반영하기 때문이다.
public class changeOrderService {
@Transactional
public void changeShippingInfo(OrderNo no, ShippingInfo newShippingInfo) {
Order order = orderRepository.findById(no);
if (order == null) throw new OrderNotFoundException();
// UPDATE 쿼리 실행
order.changeSshippingInfo(newShippingInfo);
}
}
Id 외 다른 조건으로 애그리거트를 조회할 때에는 JPA의 Criteria나 JPQL을 사용한다(Customized Query).
애그리거트를 삭제하는 기능을 위한 메서드(delete(Order order))도 적용할 수 있지만, 대게 삭제 요구사항이 있더라도 운영상의 이유로 실제로 삭제하진 않고 삭제 플래그를 사용해 노출 여부를 설정하곤 한다.
2. 매핑 구현
엔티티와 밸류 기본 매핑 구현
기본 규칙은 다음과 같다
- 애그리거트 루트는 엔티티이므로 @Entity로 매핑 설정한다.
- 한 테이블에 엔티티와 밸류 데이터가 같이 있다면,
- 밸류는 @Embeddable로 매핑 설정한다.
- 밸류 타입 프로퍼티는 @Embedded로 매핑 설정한다.
주문 애그리거트의 루트 엔티티는 Order이고, 이 애그리거트에 속한 Orderer와 ShippingInfo는 밸류인데, 이 세 객체와 ShippingInfo에 속한 Address 객체와 Receiver 객체는 아래와 같이 한 테이블에 매핑될 수 있다.
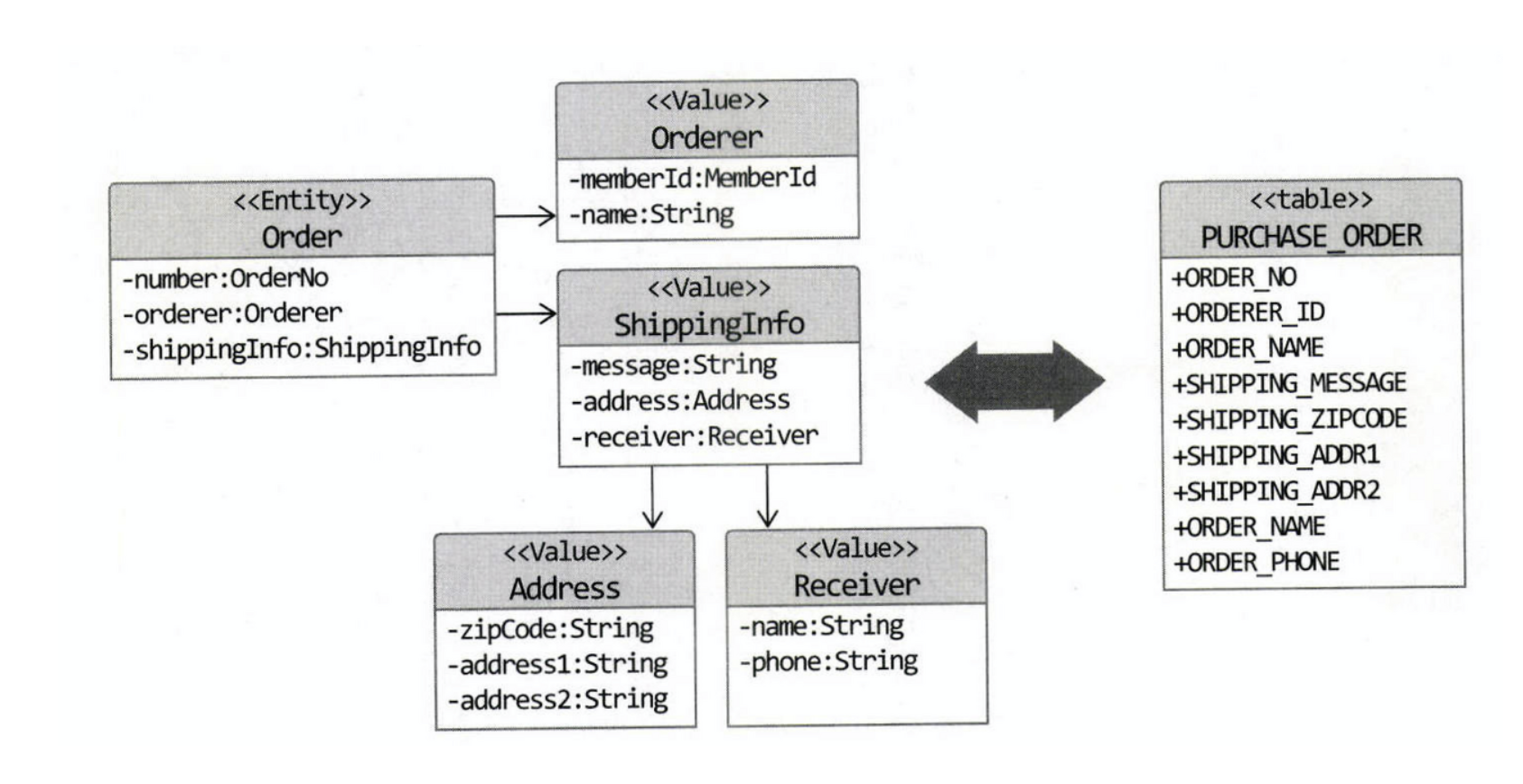
@Entity
@Table(name = "puchase_order")
public class Order {
....
@Embedded
private Orderer orderer;
}
@Embeddable
public class Orderer {
// Embeddable 타입에 설정한 칼럼 이름과 실제 칼럼 이름이 다르므로 Orderer의 memberId 프로퍼티를 매핑할 때
// @Attributeoverrides 애노테이션을 이용해 매핑할 칼럼 이름을 변경한다.
@Embedded
@AttributeOverrides(@AttributeOverride(name = "id", column = @Column(name = "orderer_id")))
private MemberId id;
@Column(name = "orderer_name")
private String name;
}
@Embeddable
public class MemberId implements Serializable {
@Column(name = "memberId")
private String id;
}
@Embbeddable
public class ShippingInfo {
// JPA 2부터 @Embeddable은 중첩을 허용하므로 밸류인 ShippingInfo가 또 다른 밸류인 Address를 포함할 수 있다.
@Embedded
@AttributeOverrides({
@AttributeOverride(name = "zipCode", column = @Column(name = "shipping_zipcode")),
@AttributeOverride(name = "address1", column = @Column(name = "shipping_addr1")),
@AttributeOverride(name = "address2", column = @Column(name = "shipping_addr2"))
})
private Address address;
@Column(name = "shipping_message")
private String message;
}
기본 생성자
엔티티와 밸류 생성자는 객체를 생성할 때 필요한 것을 전달받는다. Receiver 클래스가 불변 타입이면 생성 시점에 필요한 값을 모두 전달받으므로 값을 변경하기 위한 set 메서드를 제공하지 않는다. 이는 기본 생성자가 필요없다는 것을 뜻한다.
하지만 JPA의 @Entity와 @Embeddable로 클래스를 매핑하려면 기본 생성자를 제공해야 한다. 하이버네이트와 같은 JPA 프로바이더는 DB에서 데이터를 읽어와 매핑된 객체를 생성할 때 기본 생성자를 사용해서 객체를 생성한다. 이런 기술적 제약으로 Receiver와 같은 불변 타입은 기본 생성자가 필요없음에도 다음과 같이 기본 생성자를 추가해야 한다.
@Embeddable
public class Receiver {
...
// JPA 프로바이더가 객체를 생성할 때만 사용하기 위함이므로,
// 다른 코드에서 기본 생성자를 사용하지 못하도록 protected로 선언한다.
protected Receiver() {}
..
}
하이버네티으는 클래스를 상속한 프록시 객체를 이용해 지연 로딩을 구현한다. 이 때 프록시 클래스에서 상위 클래스의 기본 생성자를 호출할 수 있어야 하므로, 지연 로딩 대상이 되는 @Entity와 @Embeddable의 기본 생성자는 private이 아닌 protected로 지정해야 한다.
필드 접근 방식 사용
JPA는 필드와 메서드의 두 가지 방식으로 매핑을 처리할 수 있다. 메서드 방식을 사용하려면 프로퍼티를 위한 get/set 메서드를 구현해야 하는데 이렇게 되면 도메인의 의도가 사라지고 객체가 아닌 데이터 기반으로 엔티티를 구현할 가능성이 높아진다. 특히 set 메서드는 냅 데이터를 외부에서 변경할 수 있어지기 때문에 캡슐화를 깨는 원인이 될 수 있다.
엔티티를 객체가 제공할 기능 중심으로 구현하도록 유도하려면 프로퍼티의 메서드 방식이 아닌 필드 방식으로 선택해 불필요한 get/set 메서드를 구현하지 말아야 한다.
@Entity
// @Access(AccessType.PROPERTY)
@Access(AccessType.FIELD)
public class Order {
@EmbeddableId
private OrderNo number;
...
}
JPA 구현체인 하이버네이트는 @Access를 이용해 명시적으로 접근 방식을 지정하지 않으면 @Id나 @EmbeddId가 어디에 위치했느냐에 따라 접근 방식을 결정한다. 즉, 필드에 위치하면 필드 접근 방식을, get 메서드에 위치하면 메서드 접근 방식을 선택한다.
AttributeConverter를 이용한 밸류 매핑 처리
밸류 타입의 프로퍼티를 한 개 칼럼에 매핑해야 할 때가 있다. 예를 들어 Length가 길이 값인 value와 단위 값인 unit을 가지고 있을 때 DB 테이블에는 한 개 칼럼에 ‘1000mm’ 와 같은 형식으로 저장할 수 있다.
이 경우 @Embeddable로는 처리할 수 없다. JPA 2.0 버전에는 이를 위해 다음과 같이 칼럼과 매핑하기 위한 프로퍼티를 추가하고 get/set 메세드에서 실제 벨류 타입과 변환을 처리해야 했지만, JPA 2.1 에선 AttributeConverter를 사용해 변환할 수 있다.
// autoApply가 true일 경우, 모델에 출현하는 모든 Money 타입의 프로퍼티에 대해 MoneyConverter를 자동으로 적용한다.
// false인 경우, 프로퍼티 값을 변환할 때 사용할 컨버터를 직접 지정할 수 있다.
@Converter(autoApply = true)
public class MoneyConverter implements AttributeConverter<Money, Integer> {
@Override
public Integer convertToDatabaseColumn(Money money) {
if (money == null) {
return null;
} else {
return money.getValue();
}
}
@Override
public Money convertToEntityAttribute(Integer value) {
if (value == null) return null;
else return new Money(value);
}
}
밸류 컬렉션: 별도 테이블 매핑
Order 엔티티는 한 개 이상의 OrderLine을 가질 수 있다. 이러한 밸류 타입의 컬렉션은 별도 테이블에 보관한다.

ORDER_LINE 테이블은 외부키를 이용해서 엔티티에 해당하는 PURCHASE_ORDER 테이블을 참조한다. List 타입의 컬렉션은 순서를 의미하는 인덱스 값이 필요하므로 이를 위한 별도 칼럼(line_idx)도 존재한다.
밸류 컬렉션을 별도 테이블로 매핑할 땐 @ElementCollection과 @CollectionTable을 함께 사용한다.
@Entity
@Table(name = "purchase_order")
public class Order {
...
@ElementCollection
// 밸류 저장 테이블명과 외부키로 사용할 칼럼 지정
// 외부키가 두 개 이상인 경우, @JoinColumn의 배열을 이용해 외부키 목록 지정
@CollectionTable(name = "order_line", joinColumns = @JoinColumn(name = "order_number"))
// OrderLine은 List의 인덱스 값을 저장하기 위한 프로퍼티는 따로 존재하지 않는다.
// List 타입 자체가 인덱스를 갖기 때문인데, 이를 위해 JPA는 @OrderColumn 애노테이션을 이용해 지정한 컬럼에 저장한다.
@OrderColumn(name = "line_idx")
private List<OrderLine> orderLines;
...
}
@Embeddable
public class OrderLine {
@Embedded
private ProductId productId;
@Column(name = "price")
private Money price;
...
// List 인덱스 프로퍼티 따로 없음.
}
밸류 컬렉션: 한 개 칼럼 매핑
밸류 컬렉션을 별도 테이블이 아닌 한 개 칼럼에 콤마로 구분을 해서 저장해야 할 때가 있다. 이 때 AttributeConverter를 이용하여 쉽게 매핑할 수 있다. 단, 밸류 컬렉션을 표현하는 새로운 밸류 타입을 추가해야 한다. 이메일의 경우 아래 코드 처럼 이메일 집합을 위한 밸류 타입으 추가로 작성해야 한다.
public class EmailSet {
private Set<Email> emails = new HashSet<>();
private EmailSet(){}
private EmailSet(Set<Email> emails) {
this.emails.addAll(emails);
}
public Set<Email> getEmails() {
return Collections.unmodifiableSet(emails);
}
}
@Converter
public class EmailSetConverter implements AttributeConverter<EmailSet, String> {
@Override
public String convertToDatabaseColumn(EmailSet attribute) {
if (attribute == null) return null;
return attribute.getEmails().stream()
.map(Email::toString)
.collect(Collectors.joining(","));
}
@Override
public EmailSet convertToEntityAttribute(String dbData) {
if (dbData == null) return null;
String emails = dbData.split(",");
Set<Email> emailSet = Arrays.stream(emails)
.map(value -> new Email(value))
.collect(toSet());
return new EmailSet(emailSet);
}
}
@Column(name = "emails")
@Convert(converter = EmailSetConverter.class)
private EmailSet emailSet;
밸류를 이용한 아이디 매핑
식별자는 보통 문자열이나 숫자와 같은 기본 타입이기 때문에 기본적으로 @Id를 사용해 매핑하지만, 식별자의 의미를 부각시키기 위해 별도 밸류 타입으로 만들 수도 있다. 이 경우에 @Id 대신 @EmbeddedId 어노테이션를 사용한다. 이 때 JPA는 내부적으로 엔티티를 비교할 목적으로 equals() 메서드와 hashcode() 값을 사용하므로 식별자로 사용할 밸류 타입은 이 두메서드를 알맞게 구현해야 한다.
@Entity
@Table(name = "purchase_order")
public class Order {
@EmbeddedId
private OrderNo orderId;
...
}
@Embeddable
// JPA에서 식별자 타입은 Serializable 타입이어야 하므로 인터페이스를 상속받아야 한다.
public class OrderNo implements Serializable {
@Column(name = "order_number")
private String number;
// 밸류 타입의 식별자를 구현할 때 얻을 수 있는 장점은 식별자에 기능을 추가할 수 있다.
public boolean is2ndGeneration() {
return number.startWith("N");
}
}
별도 테이블에 저장하는 밸류 매핑
애그리거트에서 루트 엔티티를 뺸 나머지 구성요소는 대부분 밸류이다. 루트 엔티티 외에 또 다른 엔티티가 있다면 진짜 엔티티인지 의심해봐야 한다. 단지 별도 테이블에 데이터를 저장한다고 해서 엔티티인 것은 아니다. 주문 애그리거트도 Orderline을 별도 테이블에 저장하지만 OrderLine은 밸류이다.
밸류가 아니라 엔티티가 확실하다면 다른 애그리거트는 아닌지 확인해야 한다. 특히, 자신만의 독자적인 라이프사이클을 갖는다면 다른 애그리거트일 가능성이 높다. 예를 들어 Product와 Review를 들 수 있다. 이 둘은 같이 보여지지만 함께 생성되지 않고, 변경되지도 않으며 변경 주체도 다르다. 또한 각자의 변경이 서로에 영향을 주지 않는다. 이 때 둘 다 엔티티는 맞지만 서로의 애그리거트에 속한 엔티티는 아니다.
애그리거트에 속한 객체가 밸류인지 엔티티인지 구분하는 방법은 고유 식별자를 갖는지 여부를 확인하는 것이다. 하지만 식별자(엔티티 구성요소)를 찾을 때 테이블의 식별자(PK)와 동일한 것으로 착각하면 안된다.
예를 들어, 게시글 데이터 ARTICLE 테이블과 ARTICLE_CONTENT 테이블로 나눠서 저장할 경우 아래와 같이 두 테이블을 매핑할 수 있다.
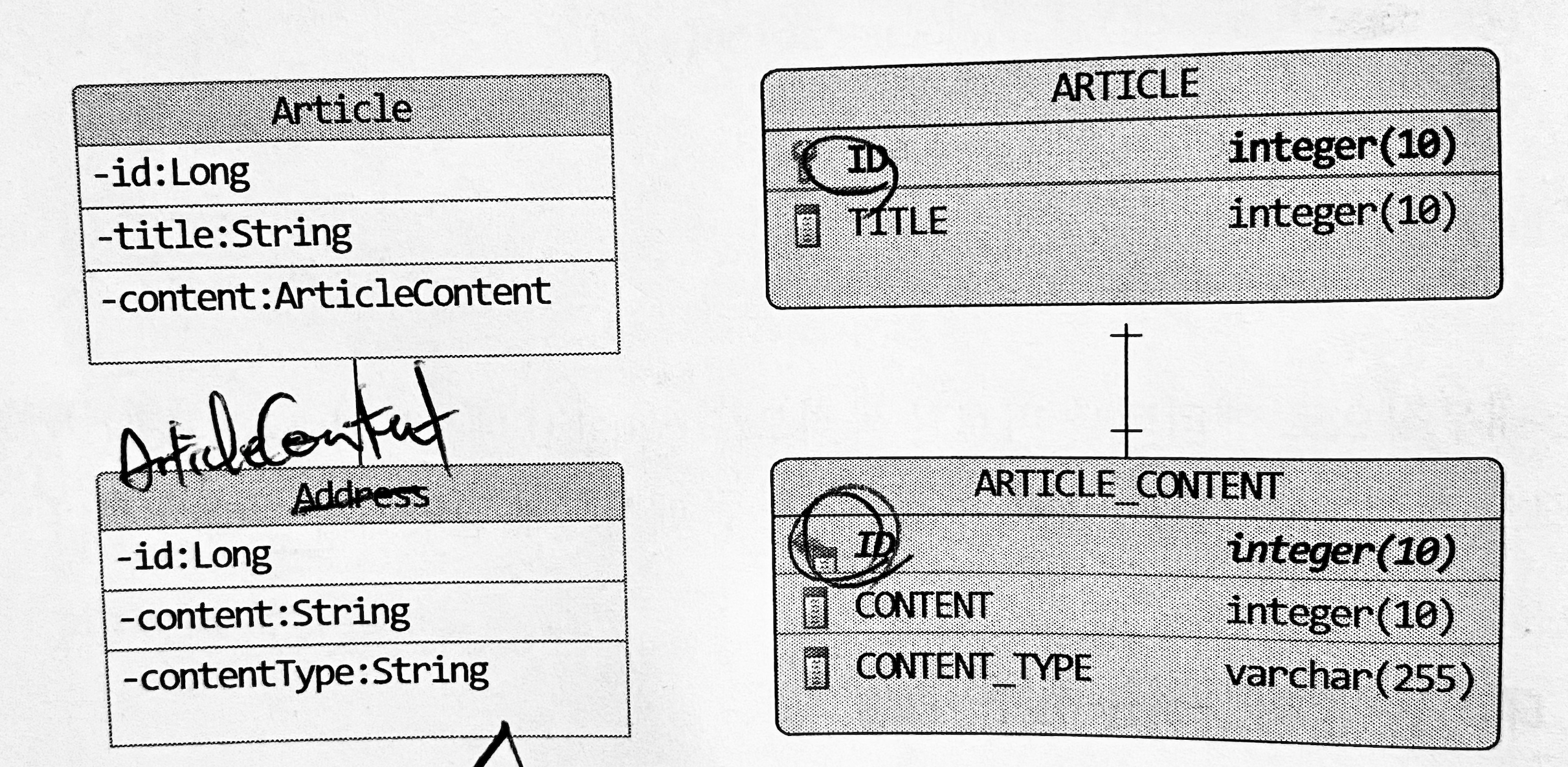
위의 경우 ArticleContent를 엔티티로 오해할 수 있어 두 엔티티 간의 일대일 연관으로 매핑하는 실수를 할 수 있다. ArticleContent는 밸류로 생각하는 것이 맞으며, ARTICLE_CONENT의 ID는 자신을 위한 별도 식별자가 아닌 ARTICLE 테이블과 연결하기 위함이기 떄문에 아래와 같은 모델로 수정해야 한다.
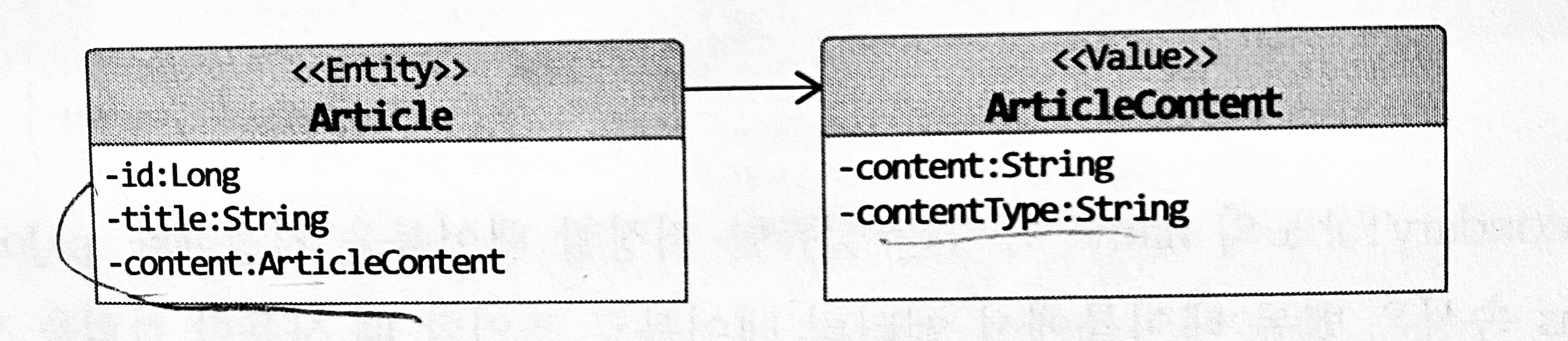
밸류를 매핑한 테이블을 지정하기 위해 @SecondaryTable과 @AttributeOverride 를 사용한다.
@Entity
@Table(name = "article")
@SecondaryTable(
name = "article_content",
pkJoinColumns = @PrimaryKeyJoinColumn(name = "id")
)
public class Article {
@Id
private Long id;
...
@AttributeOverrides({
@AttributeOverride(name = "content", column = @Column(table = "article_content")),
@AttributeOverride(name = "contentType", column = @Column(table = "article_content"))
})
private ArticleContent content;
}
@SecondaryTable을 이용하면 아래 코드를 실행할 때 두 테이블을 조인해서 데이터를 조회한다
Article article = entityManager.find(Article.class, 1L);
그러나 게시글 목록을 보여주는 화면은 article 테이블 데이터만 필요하지, article_content는 필요하지 않다. 그런데 @SecondaryTable을 사용하면 목록 화면에 보여줄 Article을 조회할 때 article_content 테이블까지 조인해서 데이터를 읽어오게 된다.
이 문제를 해결하기 위해 ArticleContent를 Entity로 매핑하고 Article에서 ArticleContent로의 로딩을 지연 로딩 방식으로 설정할 수도 있다. 하지만 이 방식은 엔티티가 아닌 모델을 엔티티로 만드는 것이므로 좋은 방법이 아니다. 대신 JPA의 조회 전용 쿼리를 실행하는 방법이 있다. (5장 참고)
밸류 컬렉션을 @Entity로 매핑하기
개념적으로 밸류인데 구현 기술 한계나 팀 표준으로 @Entity를 사용해야 할 때가 있다. 예를 들어, 이미지 업로드 방식에 따라 이미지 경로와 썸네일 이미지 제공 여부가 달라진다고 했을 때 아래와 같은 계층 구조로 설계할 수 있다.

JPA는 @Embddable 타입의 클래스 상속 매핑을 지원하지 않으므로, 상속 구조를 갖는 밸류 타입을 사용하려면 @Embeddable 대신 @Entity를 사용한 상속 매핑으로 처리해야 한다.
// 밸류를 @Entity로 매핑했으므로 상태 변경 메서드를 제공하지 않는다.
@Entity
// 하위 클래스를 매핑하므로 @Inhertance를 적용하고 SINGE_TABLE로 설정한다.
@Inheritance(startegy = InheritanceType.SINGLE_TABLE)
// 타입을 구분하는 용도로 사용할 컬럼을 지정한다.
@Descriminator(name = "image_type")
@Table(name = "image")
public abstract class Image {
...
}
@Entity
@DiscriminatorValue("II")
public class InternalImage extends Image {
...
}
@Entity
@DiscrimnatorValue("EI")
public class ExternalImage extends Image {
...
}
@Entity
@Table(name = "product")
public class Product {
...
// Image가 @Entity 이므로 목록을 담고 있는 Product는 @OneToMany를 이용해 매핑을 처리한다.
// Image는 밸류이므로 독자적인 라이프사이클을 갖지 않고 Product에 완전히 의존하기 위해 `cascade` 속성을 적용해,
// Product를 저장할 때 함께 저장되고, Product가 삭제될 때 함께 삭제되도록 설정한다.
// 또한, 리스트에서 Image 객체를 제거하면 DB에서 함께 삭제되도록 orphanRemoval도 true로 설정한다.
@OneToMany(cascade = {CascadeType.PERSIST, CascadeType.REMOVE}, orphanRemoval = true)
@JoinColumn(name = "product_id")
@OrderColumn(name = "list_idx")
private List<Image> images = new ArrayList<>();
...
public void changeImages(List<Image> newImages) {
images.clear();
images.addAll(newImages);
}
}
위의 changeImage() 메서드를 보면 이미지 교체를 위해 clear() 메서드를 사용하는데, @OneToMany 매핑에서 컬렉션의 clear()를 호출하면 삭제 과정이 효율적이지 않을 수 있다. (N+1 문제 : image 목록 조회 1번 + N번의 image 삭제 )
하이버네이트는 @Embeddable 타입에 대한 컬렉션의 claer() 메서드를 호출하면 컬렉션에 속한 객체를 로딩하지 않고 한 번의 delete 쿼리로 삭제 처리를 할 수 있다. 따라서 애그리거트의 특성을 유지하면서 이런 문제를 해소하려면 결국 상속을 포기하고 @Embeddable로 매핑된 단일 클래스로 구현해야 한다. 물론 이경우에 타입에 따라 다른 기능을 구현하기 위한 메서드가 별도로 필요하다.
ID 참조와 조인 테이블을 이용한 단방향 M:N 매핑
앞서 3장에서 애그리거트 간 집합 연관은 성능상의 이유로 피해야 한다고 했지만, 필요하다면 ID 참조를 이용한 단방향 집합 연관을 적용해 볼 수 있다.
@Entity
@Table(name = "product")
public class Product {
...
// Product 삭제시 매핑에 사용한 조인 테이블의 데이터도 함께 삭제된다.
// 따라서 영속성 전파나 로딩 전략에 대해 고민할 필요가 없어진다.
@ElementCollection
// 밸류 컬렉션 매핑과 유사하지만 집합의 값에 밸류 대신 연관을 맺는 식별자가 온다.
@CollectionTable(name = "product_category", joinColumns = @JoinColumn(name = "product_id"))
private Set<CategoryId> categoryIds;
}
3. 애그리거트 로딩 전략
애그리거트는 개념적으로 하나여야 하지만, 루트 엔티티를 로딩하는 시점에 애그리거트에 속한 객체를 모두 로딩해야하는 것은 아니다. 애그리거트가 완전해야 하는 이유는 두 가지로 볼 수 있는데, 첫 째는 상태를 변경할 때 애그리거트 상태가 완전해야 하고, 둘 째는 표현 영역에서 애그리거트 상태 정보를 보여줄 때 필요하기 때문이다.
이 중 두 번째는 별도 조회 전용 기능을 구현하면 되고, 첫 번째 상태 변경 기능을 실행하기 위해서는 조회 시점에 즉시 로딩을 이용해서 애그리거트를 완전한 상태로 로딩할 필요는 없다. JPA는 트랜잭션 범위 내에서 지연 로딩을 허용하기 때문에 아래 코드처럼 실제 상태를 변경하는 시점에 필요한 구성요소만 로딩해도 문제가 되지 않는다.
@Transactional
public void removeOptions(ProductId id, int optIdxToBeDeleted) {
Prodcut product = productRepository.findById(id);
// 트랜잭션 범위이므로 지연 로딩으로 설정한 연관 로딩 가능.
product.removeOption(optIdxToBeDeleted);
}
@Entity
public class Product {
@ElementCollection(fetch = FetchType.LAZY)
@CollectionTable(name = "product_option", joinColumns = @JoinColumn(name = "product_id"))
@OrderColumn(name = "list_idx")
private List<Option> options = new ArrayList<>();
public void removeOption(int optIdx) {
// 실제 컬렉션에 접근할 때 로딩
this.options.remove(optIdx);
}
}
4. 애그리거트 영속성 전파
애그리거트가 완전한 상태여야 한다는 것은 루트 조회 뿐만 아니라 저장, 삭제할 때도 하나로 처리해야함을 의미한다.
- 저장 메서드는 애그리거트 루트만 저장하면 안되고 속한 모든 객체를 저장해야 한다.
- 삭제 메서드도 애그리거트 루트뿐만 아니라 속한 모든 객체를 삭제해야 한다.
@Embeddable 매핑 타입은 함께 저장되고 삭제된다. 그러나 애그리거트에 속한 @Entity은 그렇지 않으므로 cascade 속성을 사용해 저장과 삭제가 함께 처리되도록 설정해야 한다. @OneToOne, @OneToMany는 cascade 속성의 기본값이 없으므로 다음 코드처럼 설정해야 한다.
@OneToMany(cascade = {CascadeType.PERSIST, CascadeType.REMOVE},
orphanRemoval = true)
@JoinColumn(name = "product_id")
@OrderColumn(name = "list_idx")
private List<Image> images = new ArrayList<>();
5. 식별자 생성 기능
식별자는 아래 세 가지 방식 중 하나로 생성된다.
-
사용자 직접 생성 (email)
-
도메인 로직 생성
별도 도메인 서비스로 식별자 생성 기능 분리해야 함. 해당 기능은 도메인 규칙이므로 도메인 영역에 위치.
또는 리포지터리 인터페이스에 정의후 구현 클래스에서 구현할 수도 있다.@GeneratedValue(strategy = GenerationType.IDENTIFY)
-
DB를 이용한 일련번호 생성
JPA는 저장 시점에 생성한 식별자를 @Id로 매핑한 프로퍼티/필드에 할당한다.