지난 포스트에 신규 프로젝트를 위해 RabbitMQ의 개념과 실제 적용을 정리해 보았는데요, 설계 단계에서 RabbitMQ 대신 Kafka를 사용하는 것으로 변경되었습니다… 때문에 RabbitMQ와 같은 메세지 큐의 또 다른 방식인 Kafka에 대해서 RabbitMQ와는 어떤 차이점이 있는지를 중심으로 정리해보았습니다.
Message Queue란?
메세지 지향 미들웨어(Message Oriented Middleware, MOM)는 서비스간 비동기 메세지를 통해 통신하는 방식을 의미합니다. 이러한 MOM을 구현한 시스템을 Message Queue(MQ)라고 합니다. 메세지 큐는 대용량 데이터, 요청에 대한 공정 작업을 연기할 수 있는 유연성을 제공하기 때문에 SOA(Service-Oreiented Architecture)의 개발에 도움을 줄 수 있습니다. 이러한 프로그램간 원활한 통신을 위해 AMQP(Advanced Message Queuing Protocol)을 따르며, 다른 벤더들 간의 통신을 쉽게 가능하게 해줍니다.
메세지 큐의 장점
- Asynchronous : Queue에 넣기 때문에 나중에 처리할 수 있습니다.
- Decoupling : 애플리케이션과 분리할 수 있습니다.
- Resilience : 일부의 실패가 전체에 영향을 주지 않습니다.
- Redundancy : 실패할 경우 재실행이 가능합니다.
- Guarantees : 작업이 완료된 것을 보장할 수 있습니다.
- Scalable : 다수의 프로세스들이 큐에 메세지를 보낼 수 있습니다.
따라서 MQ를 통해 대용량 데이터를 처리하기 위한 배치 작업, 채팅 서비스, 비동기 데이터 처리를 효율적으로 구현할 수 있습니다.
종류
이러한 Message Queue 시스템의 종류는 JMS, ActiveMQ, RabbitMQ, Kafka 등 여러가지가 있지만, 크게 RabbitMQ가 속해있는 메세지 브로커와 Kafka가 속해있는 이벤트 브로커 로 나누어 볼 수 있습니다.
메세지 브로커 vs 이벤트 브로커
메세지 브로커 (RabbitMQ)
Publisher가 생산한 메세지를 메세지 큐에 저장하고, 저장된 데이터를 Consumer가 가져갈 수 있도록 중간 다리 역할을 해주는 브로커입니다. 보통 서로 다른 시스템 간 데이터를 비동기 형태로 처리하기 위해 사용하며 이러한 구조를 일반적으로 Pub/Sub 구조라고 합니다. 이러한 메세지 브로커들은 Consumer가 큐에서 데이터를 가져가게 되면 즉시 혹은 짧은 시간 내에 큐에서 데이터를 삭제하는 특징들을 가지고 있습니다.
이벤트 브로커 (Kafka)
이벤트 브로커는 기본적으로 메세지 브로커의 모델(pub/sub)을 따르기 때문에 메세지 브로커의 역할을 할 수 있으며, 반대로 메세지 브로커는 이벤트 브로커의 역할을 할 수 없습니다.
이 때 Pub/Sub 모델은 Publisher가 topic을 통해서 카테고리화하고 분류된 메세지를 받길 원하는 Receiver는 해당 topic을 구독함으로써 메세지를 읽어올 수 있는 방식입니다. 즉, publishers는 topic에 대한 정보만 알고있고, 마찬가지로 subscriber도 topic만 바라봅니다.
이벤트 브로커는 Publisher가 생산한 이벤트(메세지)는 데이터베이스에 저장하듯 계속 저장하며, Consumer가 필요한 시점에 이벤트를 읽어가는 방식으로 동작하기 때문에, 장애가 일어나게 되면 그 이후의 이벤트들을 다시 처리할 수 있습니다.(메세지 브로커와의 차이점) 또한 대용량 데이터 처리에 있어서 더 많은 양의 데이터를 처리할 수 있는 능력이 있습니다.
Kafka의 주요 개념
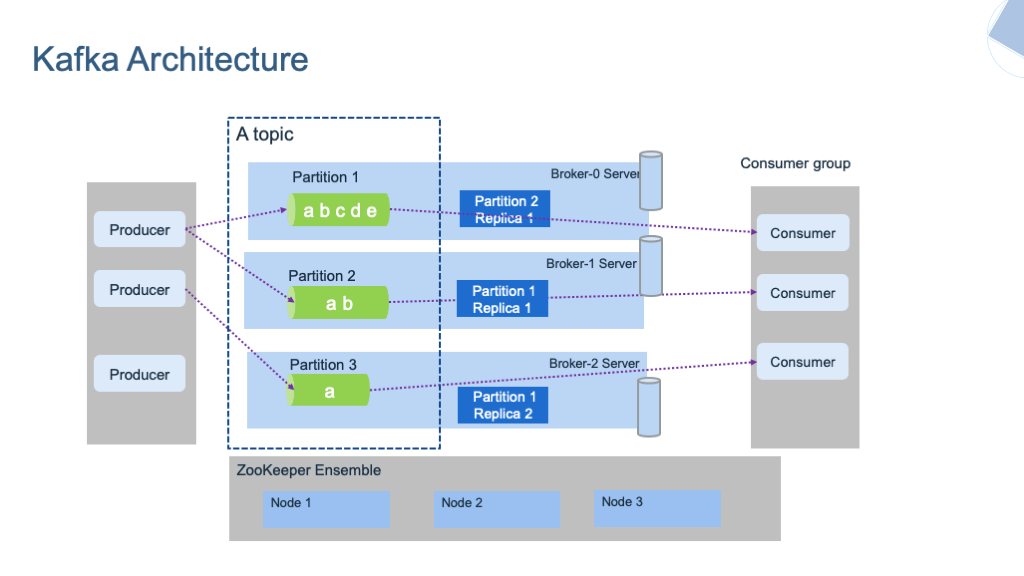
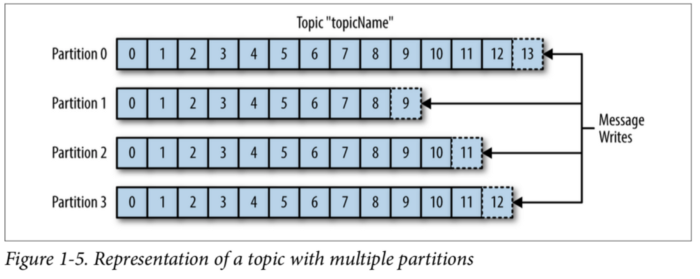
Topic과 Partition
메세지는 topic으로 분류되고, topic은 여러 개의 파티션으로 나눠질 수 있습니다. 이 때 파티션의 한 칸을 로그라고 불리며 데이터는 한 칸의 로그에 순차적으로 append 됩니다. 이러한 데이터, 즉 메세지의 상대적인 위치를 나타내는게 offset입니다.
이 때 하나의 topic에 여러 개의 파티션을 나누는 이유는 순차적으로 append되는 메세지들을 처리하는 성능을 높이기 위해 파티션을 두어 분산처리를 하기 위함입니다. 하지만 병렬로 처리됨으로써 성능은 좋아지지만 대신, 한 번 늘린 파티션은 다시 줄일 수 없기 때문에 운영중에 파티션의 개수는 신중히 고려해봐야 합니다. 또한 각 파티션으로 메세지는 Round-Robin 방식으로 쓰여지기 때문에 순차적으로 쓰여지지 않아 메세지의 순서가 중요한 모델(증권시스템)이라면 상당히 위험할 수 있습니다.
Producer와 Consumer
앞서 RabbitMQ의 주요개념에서 알아본 것과 같은 개념입니다. 다른 특징으로 Kafka의 Producer는 특정 메세지들을 분류하여 특정 파티션에 저장하고 싶을 때, key 값을 통해 분류해서 넣을 수 있습니다. 또한 Consumer는 topic을 구독하고 읽어들인 각 파티션의 offset을 저장, 관리함으로써 죽었다가 다시 살아나도 전에 마지막으로 읽었던 위치로부터 다시 읽어들일 수 있습니다. 즉, fail-over에 대한 신뢰가 존재합니다.
Consumer Group
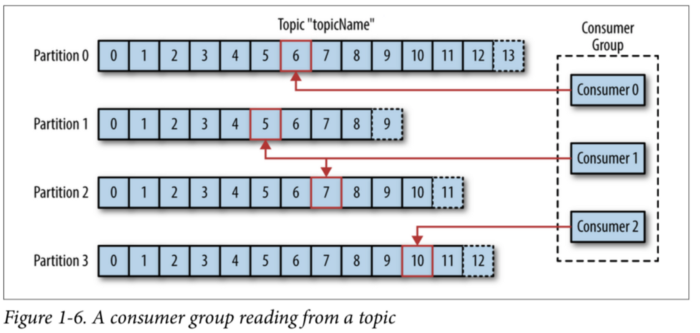
말 그대로 consumer들의 묶음이고, 반드시 해당 topic의 파티션은 그 consumer group과 1:N 매칭을 해야합니다. 따라서 아래의 케이스가 존재합니다.
case1) consumer 중에 하나는 2개의 파티션을 소비
case2) consumer 중에 하나는 1개의 파티션을 소비
case3) consumer 중에 하나는 아무 것도 하지 않음
따라서 파티션을 늘릴 때는, Consumer의 개수도 고려해야 합니다. 보통 개수를 맞춰주는 것을 권장하지만, 실제 메세지가 쌓이는 속도보다 처리하는 속도가 훨씬 빠르다면 굳이 1:1 매핑보다는 파티션 개수를 더 많이 설정하는 것도 나쁘지 않습니다.
위의 케이스를 보면 case3와 같은 경우도 있는데도 불구하고 따로 Consumer Group이 존재하는 이유는 하나의 Consumer Group이 하나의 Topic에 대한 책임을 갖고 있기 때문입니다. 예를 들어 Partition 1을 유일하게 구독하던 그룹 내 Consumer 1이 다운이 된다면 Partition 1 을 관리하기 위해 Rebalancing 이 일어나게 되고 그룹내 다른 Cosumer가 이를 대신해 Partition 을 구독하게 됩니다. 이 때 그룹 내에서 offset 정보를 서로 공유하고 있기 때문에 이러한 처리를 진행할 수 있습니다.
Broker, Zookeeper
Broker는 카프카의 서버를 의미하며 broker.id = 1,…,N 으로 함으로써 동일한 노드 내에서 여러 개의 브로커 서버를 띄울 수도 있습니다. Zookeeper는 이러한 분산 메세지 큐의 정보를 관리해주는 역할을 합니다. 따라서 Kafka를 띄우기 위해서는 Zookeeper가 반드시 실행되어야 합니다.
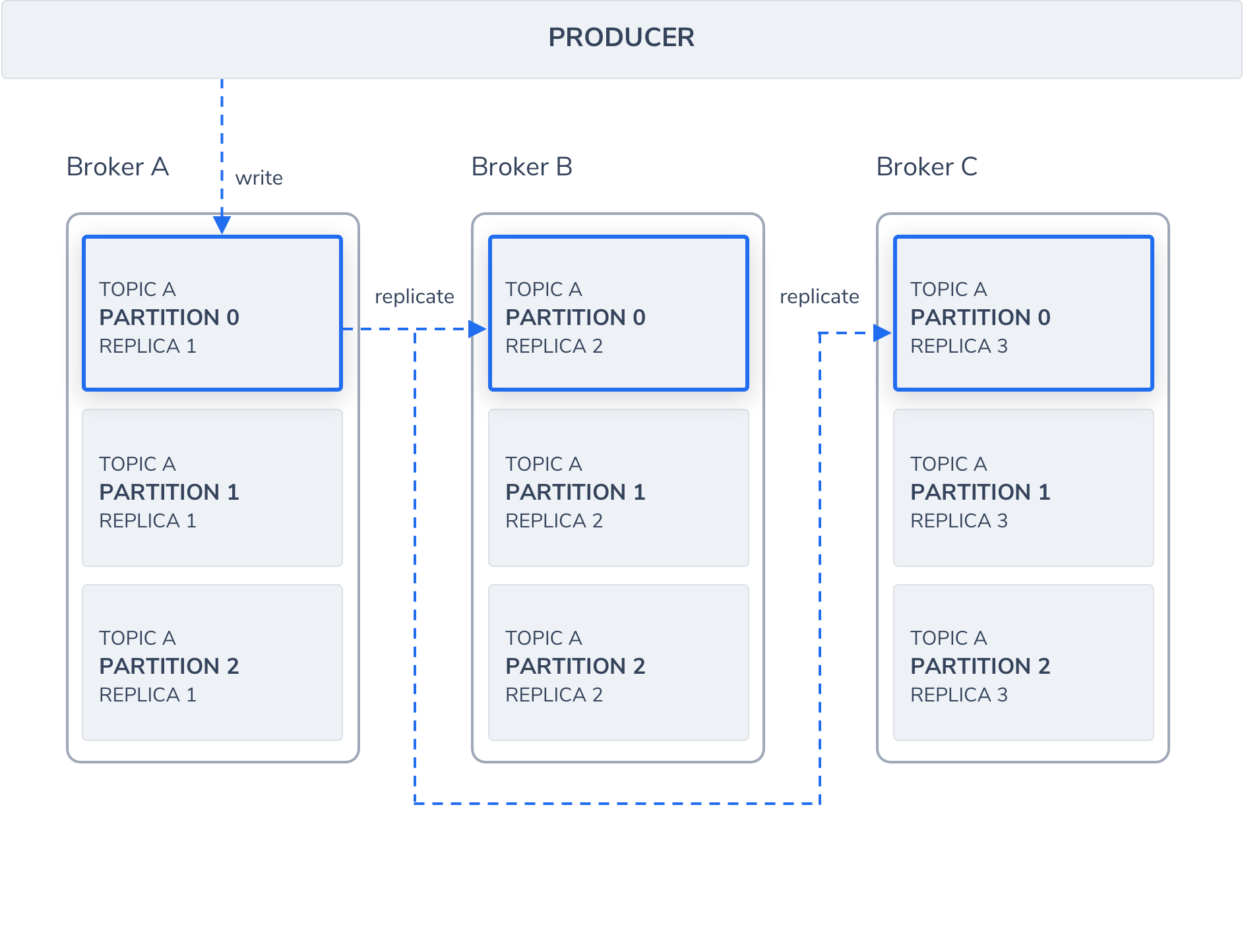
Replication
카프카는 더 강한 내구성(Durability)과 오류 발생 시 더 높은 가용성을 위해 파티션을 복제하고 여러 브로커 서버에 배포할 수 있습니다. 예를 들어 replica-factor=3 설정으로 Local에 3대의 Broker를 띄웠을 경우, 이 때 복제는 수평적인 스케일 아웃(Scale-out) 입니다. 3대에서 하나의 서버만 Leader가 되고 나머지 2대는 Follower가 되는데, Producer가 메세지를 쓰고 Consumer가 메세지를 읽는 건 오로지 리더가 전적으로 담당하며 팔로워들은 리더와의 싱크를 항상 맞추고 있습니다. (해당 option 있음.) 혹시나 리더가 죽었을 경우, 나머지 팔로워 중 하나가 리더로 선출되어 작업을 이어서 진행합니다.
Kafka vs RabbitMQ
1. Message Retention
Kafka : by policy
RabbitMQ : by acknowledge
Kafka의 메세지 보유기간은 설정된 poilcy 기간 동안 유지되어, 동일한 메세지를 반복적으로 처리할 수 있는 반면 RabbitMQ의 경우 ack를 받은 메세지는 사라지게 됩니다. 이 때 처리를 완료한 메세지를 재처리하고 싶은 경우에는 반드시 Producer가 메세지를 republish 해야 합니다.
2. Message Routing
Kafka : -
RabbitMQ : Exchange
Kafka는 별도의 라우팅이 존재하지 않아, Publisher가 적절한 topic과 partition으로 메세지를 publish 해야하는 반면, RabbitMQ의 exchange는 direct/fanout/topic 등 다양한 기능을 제공합니다. exchange가 routing key에 따라서 메세지를 적절한 큐에 분배합니다.
3. Multiple Consumer
Kafka : topic-partition-one consumer per partition, guaranteed order
RabbitMQ : multiple consumer per queue, not guaranteed order
Kafka는 topic의 각 partition에는 하나의 consumer만 메세지를 처리할 수 있어 메세지 처리 순서가 보장됩니다. (주의: 파티션 내의 순서는 보장되지만 topic의 전체 순서는 보장하지 않습니다.) 반면 RabbitMQ는 하나의 Queue에 여러 개의 Consumer가 허용되어 메세지 처리 순서가 보장되지 않습니다.
4. Consumer Push/Pull Model
Kafka : consumer pull from Kafka topic
RabbitMQ : push message to consumer
Kafka는 consumer가 카프카에서 메세지를 pull 하고 RabbitMQ는 rabbitMQ가 consumer에게 직접 메세지를 push 합니다.
5. Performance
Producer 성능
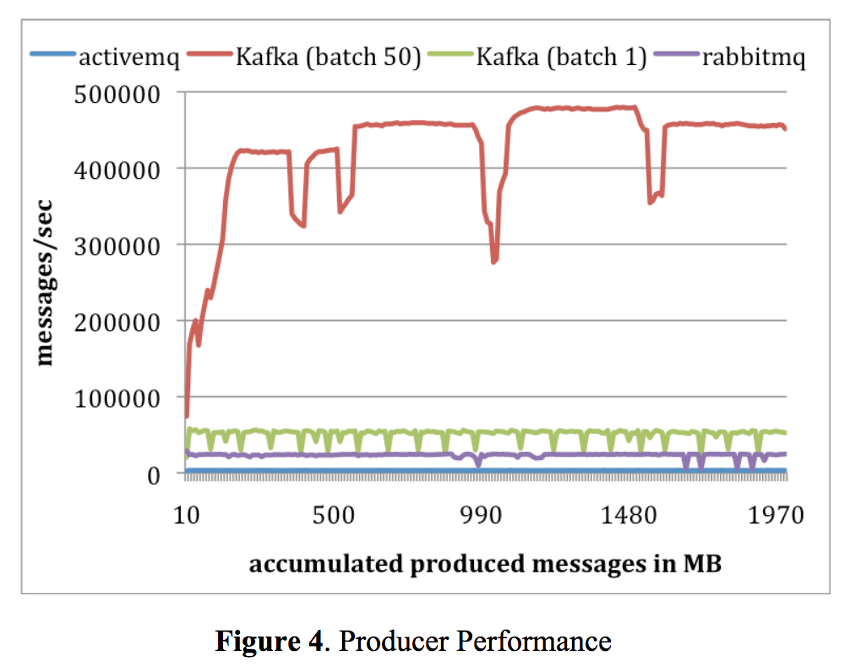
- 카프카 생산자는 브로커로부터 ACK를 기다리지 않고 메세지를 보내기 때문에 브로커가 핸들링할 수 있는 만큼 빠르게 마구 보낼 수 있습니다.
- 카프카는 좀 더 효율적인 저장소 포맷을 가지고 있습니다. 평균적으로 카프카의 각 메세지들은 9byte의 오버헤드를 가지는 반면, ActiveMQ 에서는 144bytes를 가지는데, 이것은 메세지 헤더때문으로 JMS에 의해 요구되어진 것과 다양한 인덱싱구조를 유지하기위한 것입니다.
Consumer 성능
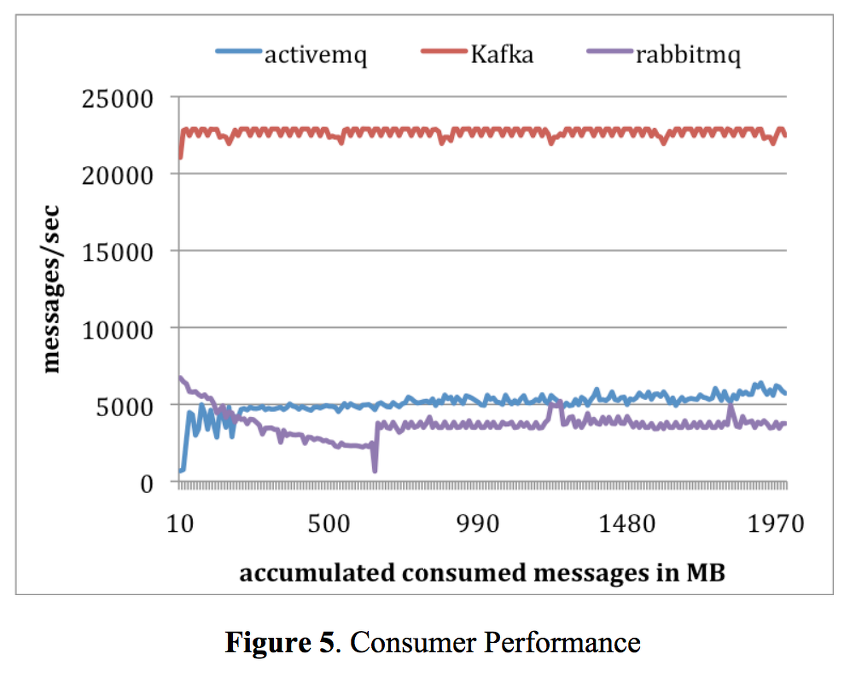
결론
Kafka가 적절한 곳
Kafka는 복잡한 라우팅에 의존하지 않고 최대 처리량으로 이벤트 소싱, 스트리밍을 하는 데 적합합니다. 즉, 스트리밍 데이터를 저장, 읽기, 다시 읽기 및 분석하는 프레임워크가 필요한 경우 또는 정기적으로 감시하는 시스템이나 메세지를 영구적으로 저장하는데 적합합니다.
“실시간 처리”
RabbitMQ가 적절한 곳
복잡한 라우팅이 필요하면서 신속한 요청-응답이 필요한 웹 서버에 적합합니다. 또한 부하가 높은 작업자 간에 부하를 공유하기 때문에 RabbitMQ는 백그라운드 작업이나 PDF 변환, 파일 검색 또는 이미지 확장과 같은 장기 실행 작업 처리에 적합합니다.
“장시간 실행되는 태스크, 안정적인 백그라운드 작업, 애플리케이션 간 내부 통신 및 통합”
Reference
- https://coralogix.com/blog/a-complete-introduction-to-apache-kafka/
- https://medium.com/@umanking/%EC%B9%B4%ED%94%84%EC%B9%B4%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C-%EC%9D%B4%EC%95%BC%EA%B8%B0-%ED%95%98%EA%B8%B0%EC%A0%84%EC%97%90-%EB%A8%BC%EC%A0%80-data%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C-%EC%9D%B4%EC%95%BC%EA%B8%B0%ED%95%B4%EB%B3%B4%EC%9E%90-d2e3ca2f3c2
- https://minholee93.tistory.com/entry/RabbitMQ-RabbitMQ-vs-Kafka